
Si usted tiene una cuenta en una red social como Facebook o Twitter o usa buscadores de precios como Booking.com o portales de entretenimiento como Netflix, seguramente haya formado parte (consciente o no) de algún experimento masivo, conocidos como Experimentos A/B. La idea detrás es sencilla. Se producen dos versiones de una página web que difieren en una variable que puede modificar el comportamiento del usuario. Los usuarios se dividen en dos grupos, A y B, elegidos aleatoriamente, y se compara su comportamiento para obtener información sobre las dos alternativas. Como trataré de explicar en esta entrada, es precisamente el componente aleatorio (y no el hecho de que las muestras sean gigantescas) lo que nos permite evaluar cada versión.
La mayoría de estos experimentos tienen por objeto examinar las prestaciones del entorno web o del contenido, pero el método se usa también para obtener información acerca de las preferencias de los usuarios. Por ejemplo, Expedia.com necesita obtener información sobre las preferencias de los consumidores respecto a cuáles son los mejores hoteles pero no puede fiarse simplemente de sus elecciones ya que estas están afectadas por el propio ranking (Ursu, 2016). Para evitar este problema de endogeneidad, el portal realiza un experimento en el que algunos usuarios observan un ranking aleatorio (A) mientras que el resto observa el ranking estándar (B). Si la muestra de consumidores es suficientemente grande y representativa, los hoteles con más demanda en el grupo A serán los que tengan mayor atractivo para todos los usuarios. Como subproducto, la compañía obtiene una medida del valor que tiene para las empresas aparecer en las primeras posiciones del ranking, que es justamente el retorno para los hoteles de la comisión que pagan al portal.
El campo donde los experimentos AB son más útiles es, sin duda, el estudio de la rentabilidad de campañas de marketing. Esto se debe a tres motivos. El primero es que estimar el retorno de la inversión para el anunciante es tremendamente complicado (Lewis y Rao 2015). El segundo es que el diseño del experimento es particularmente sencillo y no tiene costes adicionales para el usuario. Los consumidores del grupo A son elegibles para la campaña y estarán expuestos al anuncio con una cierta probabilidad, mientras que los consumidores del grupo B son inelegibles para la campaña, por lo que estarán expuestos al anuncio que hubiera sido seleccionado por el algoritmo del portal si el experimento no tuviera lugar. En la mayoría de casos, este es el anuncio cuya puja en la subasta para el grupo de la población a la que pertenece este individuo finalizó en segundo lugar.
El tercer motivo tiene que ver con el propio diseño de las campañas publicitarias y es el objeto de un estudio reciente de Gordon, Zettlemayer, Barghava y Chapsky. Naturalmente, el objetivo de la campaña es maximizar el impacto de la publicidad en los consumidores y, por tanto, los consumidores expuestos a los anuncios diferirán sustancialmente de aquellos no expuestos. La solución habitual para evaluar el impacto de la campaña es utilizar técnicas econométricas para estimar las ventas en el mundo contrafactual en el que el grupo de consumidores expuesto no hubiera visto el anuncio.
Aunque las técnicas son diversas, los autores las dividen en dos tipos. Las estrategias de matching o emparejamiento construyen un grupo de control compuesto de individuos no expuestos para cada individuo del grupo expuesto, utilizando aquellas variables observables que determinan conjuntamente la exposición y la respuesta. Por ejemplo, si el anunciante es un fabricante de perfumes las variables relevantes serán el género, la edad, el lugar de residencia, nivel de ingreso, etc. Asumiendo que no hay variables inobservables que afecten significativamente al nivel de exposición y al comportamiento y que tenemos suficientes observaciones, el estimador de emparejamiento se aproximará mucho al que obtendríamos con el experimento A/B.
El segundo tipo de estrategia usa los llamados estimadores de ajuste de regresión (regresión-adjustment), que construyen el contrafactual estimando la relación entre las variables observables y la probabilidad de adquirir el producto entre los consumidores que no están expuestos a la campaña, con la idea de que la relación subyacente en el grupo expuesto será la misma. Por tanto, la diferencia entre la probabilidad de adquisición de producto del grupo tratado y la probabilidad hipotética obtenida mediante el ajuste de regresión debería aproximarse al resultado del experimento.
Hasta aquí la teoría. ¿Qué nos dice la evidencia? Para responder a esta pregunta Zettlemayer y sus coautores estudian 13 experimentos AB en Facebook, donde comparan el resultado de la estimación del tratamiento experimental (entre el grupo tratado y el de control) y los resultados de los distintos tipos de técnicas no experimentales (usando el conjunto de usuarios no expuestos como control).
He tratado de resumir los resultados en la Gráfica 1. Cada punto en el gráfico corresponde al valor estimado del incremento relativo en la probabilidad de adquirir un producto en cada campaña, usando las diversas técnicas descritas anteriormente. Los puntos azules (naranjas) son aquellos en los que (no) se rechaza la hipótesis nula de que el resultado de la técnica experimental es igual al del experimento A/B.
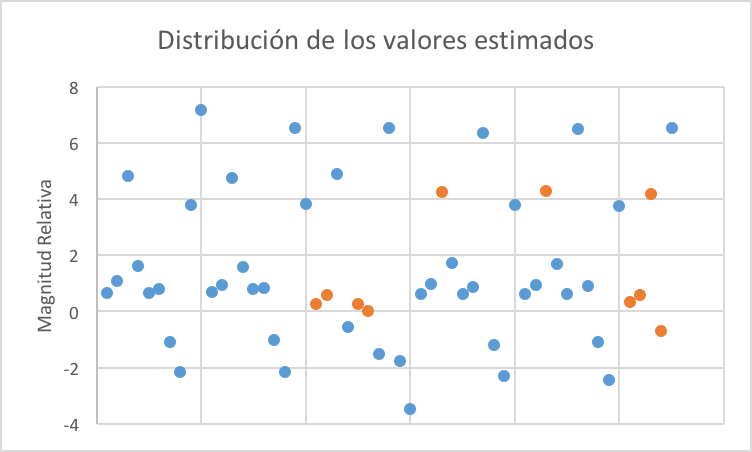
Figure 1: Cada punto corresponde a una estimación en cada uno de los 10 experimentos seleccionados. La magnitud relativa está calculada como el logaritmo del ratio entre el valor estimado por la técnica no experimental y el valor estimado en el experimento. Valores negativos corresponden a observaciones en los que los dos valores difieren de signo.
Los resultados son desalentadores. La mayoría de técnicas no experimentales sobreestiman el efecto de la campaña. La razón fundamental es que el algoritmo de Facebook elige qué usuarios del grupo tratado observan el anuncio con el fin de maximizar la proporción de usuarios que hacen clic en el banner. Aunque los investigadores incluyen como control la mayoría de las variables que utiliza Facebook para asignar anuncios, el algoritmo de Facebook es mucho más sofisticado que el modelo de regresión que usan los investigadores, por lo que el resultado más normal es que se produzca selección positiva en el grupo expuesto, y por tanto, se sobreestime el efecto.
La Tabla 2 muestra la magnitud potencial del problema. En este caso, la selección del algoritmo es tan eficiente que el efecto estimado con las técnicas no experimentales es enorme: la probabilidad de venta de aquellos que ven el anuncio es, al menos, 15 veces mayor que la de aquellos que no lo ven. Lamentablemente para esta empresa, el efecto real es nulo.
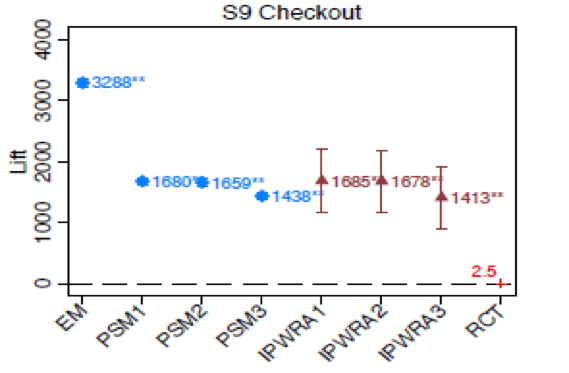
Figure 2: Cada observación es un método de estimación del efecto de la campaña en el Experimento 9. Las bandas representan los intervalos de confianza al 99%. RCT es el estimador experimental, PSM y EM son los estimadores de emparejamiento y IPVRA son los estimadores de ajuste de regresión.
Más allá de este caso concreto, el artículo nos debería hacer reflexionar sobre la importancia de utilizar evidencia experimental (RCTs) para evaluar políticas (públicas o no). Este es un tema que se ha tratado mucho en NadaEsGratis (por ejemplo, aquí aquí, aquí y aquí), pero sobre el que seguramente, y aún a costa de resultar plomizos, debamos seguir insistiendo.
Hay 7 comentarios
Por favor, Podrías explicar mejor este párrafo. Muchas gracias
"El segundo es que el diseño del experimento es particularmente sencillo y no tiene costes adicionales para el usuario. Los consumidores del grupo A son elegibles para la campaña y estarán expuestos al anuncio con una cierta probabilidad, mientras que los consumidores del grupo B son inelegibles para la campaña, por lo que estarán expuestos al anuncio que hubiera sido seleccionado por el algoritmo del portal si el experimento no tuviera lugar. En la mayoría de casos, este es el anuncio cuya puja en la subasta para el grupo de la población a la que pertenece este individuo finalizó en segundo lugar."
Quizá quede más claro con un ejemplo. Suponga que la intervención se trata de informar a un grupo sobre los beneficios de usar un anticonceptivo. Para poder estimar el efecto de la charla al grupo de control se le debe dar una charla de cualquier cosa que no afecte su demanda de anticonceptivos. Esto es costoso para la campaña y seguramente también para los miembros del grupo de control. En el caso de la campaña publicitaria el grupo de control ve el mismo anuncio que hubieran visto en caso de que la campaña no existiera. Si Facebook usa una "position auction" para determinar qué anuncios ve un determinado usuario, y a ese usuario se le asigna el grupo de control y la subasta la gana la campaña, al usuario se le muestra el anuncio de la empresa que quedó en segundo lugar (que hubiera quedado primera de no haber sido por la campaña).
Entrada muy interesante. Al hilo de esta dejo un paper de Deaton et al. (2016) que habla sobre lo qué son capaces de hacer los RCT y lo que no.
Reference: Deaton, Angus, and Nancy Cartwright. 2016. “Understanding and Misunderstanding Randomized Controlled Trials.” NBER Working Paper, no. 22595.
Gracias!
Totalmente de acuerdo con el artículo que mencionas. En este caso, el RCT no nos permite saber porqué unas veces funciona y otras no y poco puedo decir de la validez externa sin un modelo sobre cómo los consumidores deciden si adquirir o no productos anunciados.
¡Qué interesante! Gracias Daniel
Hola Daniel, muchas gracias por la entrada, muy interesante. Además me pilla cercana, como trabajador de Booking.com. Ésta, como las otras compañias que mencionas, se basan en la innovación y sus decisiones son data-driven, a lo que se le pone especial hincapié.
Tan solo mencionar, lo que parece un error, el artículo de (Ursu, 2016) esta basado en un experimento de Expedia, no de Booking.com.
Me quedo con ganas de saber más. Especialmente interesante es el impacto que tiene para el hotel su posición en el ranking, que por el artículo deduzco es menor de lo que pensaba.
Carlos,
¡Muchas gracias! Siento mucho la confusión. Ya lo he editado. Había pensado escribir sobre esto pero luego me pareció más relevante lo de la causalidad y no comprobé la referencia como debiera. Gracias de nuevo.
Respecto a lo que plantea, el efecto creo que es importante (aunque es posible que en la industria se tenga otra percepción a juzgar por la entrevista de Tans en ElPaís). Si nos fijamos en la estimación en forma reducida, aproximadamente la mitad del efecto de posición no causal en la tasa de click-through se debe a la posición. Además el experimento puede tener un sesgo "de atenuación". Un consumidor habitual que tenga una idea de los hoteles del destino al que se dirige y vea un ranking aleatorio puede comportarse de manera distinta que si el ranking fuera el habitual. Esto podría explicar porqué el efecto en la tasa de conversión es cero.
Un saludo
Los comentarios están cerrados.