
Internet está llena hoy de discusiones sobre la última encuesta electoral de El País. Muchos analistas discuten las implicaciones políticas de la misma. Otros dudan sobre la estabilidad de la intención de voto o sobre como Metroscopia imputa intención de voto estimada a partir de intención de voto declarada.
Mientras que todos estos comentarios son importantes, algo que no he visto discutido es una propiedad de las encuestas cuando nos movemos de una situación de bipartido a una de tripartidismo (o, si se consolida el éxito de Ciudadanos en esta encuesta, al cuatripartidismo).
Realizar un muestro en una situación donde solo dos opciones son relevantes (¿vas a votar al partido A o al partido B?) es mucho más fácil que realizar muestro cuando varias opciones son relevantes (¿vas a votar al partido A, al partido B, o al partido C?). Si empleamos el lenguaje de la teoría de la probabilidad, al realizar una encuesta estamos obteniendo una muestra de una distribución multinomial, donde el número de pruebas son las entrevistas realizadas y los parámetros de la distribución son la verdadera intención de voto. No quiero aburrir al lector con los detalles de esta distribución (la página de wiki los explica) pero ¿qué ocurre, de manera simplificada, cuando tenemos más partidos competitivos con la precisión de nuestra estimación de voto?
Para ilustrar este fenómeno sin recurrir a las matemáticas voy a presentar una pequeña simulación (por cierto, a mi me gusta enseñar estadística de esta manera; es mucho más intuitivo) ([1]).
Voy a simular, bajo dos escenarios, 5.000 encuestas de 1.000 entrevistas (el mismo número de entrevistas que la de El País). Es decir, estamos imaginando que existen 5.000 “Españas paralelas” y en cada una de ellas se realiza una encuesta de 1.000 entrevistas. En Matlab, el código de la simulación son 30 líneas que se escriben en menos de 5 minutos y se corre en menos de 1 segundo (incluídos los gráficos).
En el primer escenario solo existen dos partidos, A y B. La verdadera intención de voto es 55% para el partido A y 45% para el partido B. En las 5.000 encuestas, el partido A obtiene entre el 48.9% y el 60.2% del voto estimado mientras que el partido B obtiene entre el 39.8% y el 51.1%. Mientras que el rango de porcentaje de votos esperado es relativamente amplio (como un 11%), la victoria de A es clara: en 4.997 de las 5.000 encuestas simuladas, el partido A gana las elecciones.
Mirando las 5.000 encuestas una a una, lo que se ve es que casi todas ellas te dan 53-57% vs. 43%-47%, excepto en unas poquitas, donde o A sale un poco mejor parado (y se te a va al 60.2%) o B lo hace francamente bien (y se te va al 51.1%). El histograma de respuestas lo cuelgo en la siguiente figura, donde en azul dibujo al partido A y en magenta al partido B. Los histogramas apenas se solapan. Incluso si redujésemos la distancia de voto real a 52%-48%, los histogramas aun se distinguirían fácilmente.

Este seria el caso de Estados Unidos, donde solo existen dos partidos relevantes (el Republicano y el Demócrata). En cuanto tienes una muestra relativamente grande y la diferencia de voto no es muy, muy ajustada, las encuestas bien hechas (hay muchas muy malas o simplemente manipuladas) aciertan casi siempre. Este solía ser el caso también, en cierta medida en España, ya que a nivel nacional teníamos un bipartidismo muy acusado, con una IU y UPyD muy pequeños. De manera muy simplificada, el primer escenario era España en 2008 o 2012 si nos centrábamos en el PP y PSOE: dos opciones con cierta distancia entre ellas (en favor del PSOE en 2008, en favor del PP en 2012).
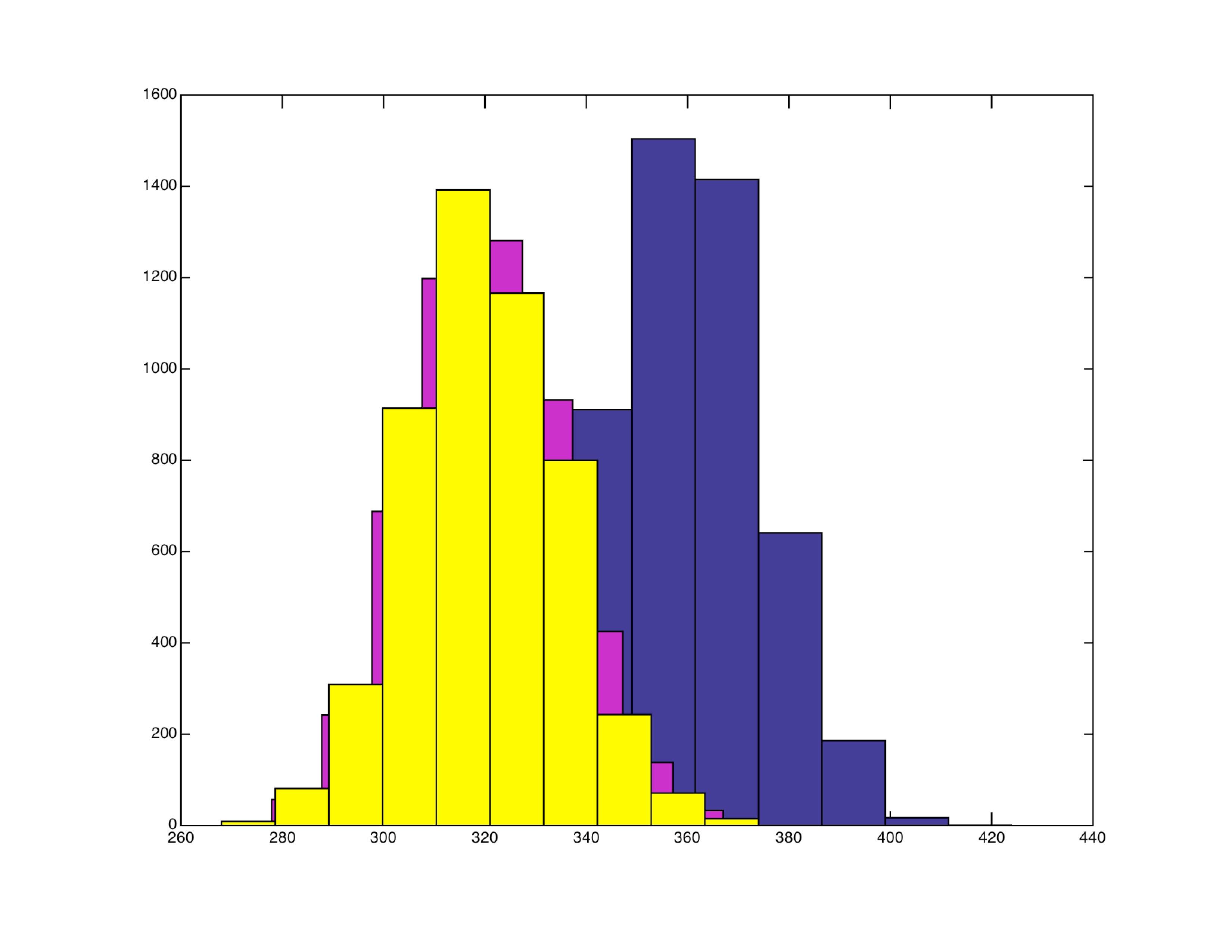
En el segundo escenario existen tres partidos, A, B y C. La verdadera intención de voto es 36%, 32% y 32%. Es decir tenemos más opciones y las distancias son más reducidas (como parece ser el caso ahora en España). En las 5.000 encuestas, el partido A obtiene entre el 29.9% y el 42.4% del voto estimado, el partido B entre el 26.8% y el 36.7% y el partido C entre el 26.8% y el 37.4%. Y a pesar de tener una ventaja de 4%, el partido A solo gana en 4.439 de las 5.000 encuestas.
De nuevo esto se ve en la figura, donde azul sigue siendo A, magenta es B y ahora tenemos en amarillo a C. Claramente, los histogramas se solapan uno encima del otro. En otras palabras, cuando tenemos tres partidos relativamente cercanos unos al otro, las encuestas tienen un rango de posibilidades muy amplio, con victorias de C, victorias de B y victorias de A.
El añadir a estas simulaciones a Ciudadanos, IU, UPyD y los partidos nacionalistas, y con ello incrementar las varianzas estimadas, solo hace que reforzar mi mensaje: con 1.000 entrevistas, el nivel de incertidumbre de una encuesta en España, sin ni siquiera incluir muchos otros problemas estadísticos (como la calidad del muestreo cuando el votante de la tercera nueva opción puede ser sistemáticamente diferente por ejemplo en su distribución geográfica o en su disposición a contestar al encuestador), es muy alto.
De hecho donde este fenómeno se veía ya era en las encuestas a las elecciones autonómicas del Pais Vasco y Cataluña (y en menor medida Galicia y Valencia), en los que la superposición de un sistema de partidos nacional con un sistema de partidos local incrementaba notablemente las posibilidades y donde se veían resultados electorales finales algunas veces alejados de las predicciones ([2]).
¿Es la encuesta de El País informativa? Sí, pero con muchísima incertidumbre. En mi opinión, el 95% del comentario en internet hoy es por ello irrelevante.([3])
1. El aumento de la incertidumbre se produce por el aumento de la entropía en la muestra cuando el número de eventos relevantes crece. Este aumento aparece por dos mecanismos (recogidos en mis simulaciones). El primero es que con las mismas 1,000 observaciones tenemos que estimar más parámetros y por tanto los intervalos de confianza (frecuentistas) o las posterioris (Bayesianos) serán más amplios. Una manera trivial de pensarlo es imaginar una muestra con 1,000 entrevistas y 1,000 partidos con posibilidades de obtener votos. La información que contiene la muestra sobre la intención de voto para el partido 347 ha de ser a la fuerza muy reducida. Pero además asumo que multipartidismo también supone que las distancias entre los partidos se reducen de media. Si tenemos tres partidos en disputa, es más complejo que haya diferencias de 16 puntos como hubo entre el PP y el PSOE en 2011. No solo se incrementa el rango del intervalo de confianza, sino que además crece como porcentaje de la estimación puntual de intención de voto y de las diferencias de intención de voto.
2. Mi afirmación sobre los problemas relativos de las encuestas en ciertas elecciones autonómicas está basada en una impresión personal de haber leído encuestas en España y seguir la política en detalle por 25 años; desconozco si alguien ha realizado una investigación detallada de esta impresión y reconozco que la misma puede ser claramente refutada por los datos. Desafortunadamente carezco de los medios o del tiempo para recopilar estos datos para esta entrada del blog.
3. He modificado la entrada un poco unas horas después de haberla publicado por primera vez. Me ha tocado hoy esperar 45 minutos para cenar y mientras estaba en la cola del restaurante, he tenido tiempo de refinar los argumentos con respecto a la primera versión. Si alguno está por San José y no le importa esperar o comer en un sitio bastante cutre, las gambas con salsa sha-bang mild merecen la pena.
Hay 18 comentarios
Y una cuestión no menor es que estas encuestas no hablan de la traslación a escaños, que al final es lo que decide el rumbo político. Cuando hay 3 ó 4 formaciones, el sistema D´Hont puede hacer diabluras en una circunscripción ante pequeños cambios en los votos, de modo que un pequeña variación entre el porcentaje de votos estimado y el real puede hacer que cambien muchos escaños en muchas circunscripciones, lo que hace que la varianza de los estimadores del porcentaje de voto de cada partido tenga incluso mayor importancia.
Un cordial saludo.
Por favor, dejemos de acusar a D'Hont. EL problema que planteas se produce por el reducido tamaño de las circunscripciones electorales. En este artículo expongo las razones: http://www.malagahoy.es/article/opinion/1130787/la/ley/dhont/es/inocente.html
Saludos
Muchas gracias por su enlace, Che Cabello. Yo no entro a criticar la ley D'Hont. Simplemente digo que, constatada la realidad de que existen muchas circunscripciones medianas y pequeñas que usted comenta, hay una tendencia a que muchos escaños puedan cambiar por un puñado de votos, lo cual es más fácil cuantos más partidos haya con un voto suficiente como para luchar por obtener representación en una circunscripción. Por ejemplo, con tres partidos prácticamente empatados, en una circunscripción con 4 escaños, cada partido se llevará 1 escaño, pero el cuarto dependerá de cuál sea la fuerza más votada (si suponemos que saca más del doble que la cuarta fuerza más votada). Quizá esa cuarta fuerza, al fragmentarse el voto, pueda tener opciones de tener representación. Para los otros 3 partidos, normalmente (si no hay una cuarta fuerza con representación), ser la fuerza más votada les puede suponer obtener el doble de escaños que si son la segunda o la tercera, lo que puede depender de un puñado de votos. Cuanta mayor sea la varianza de los estimadores de la proporción de votos que pueda sacar cada partido, mayor será el riesgo de cometer errores importantes, ya que si esa situación es semejante en 15 circunscripciones (muchas circunscripciones tienden a parecerse), podemos ver bailar a la vez 15 escaños por desviaciones pequeñas en el porcentaje de votos real sobre lo previsto. Pero eso no quiere decir que, por eso, la ley D'Hont sea buena o mala, sino solamente un reto para las encuestas.
Un cordial saludo.
Perdón por la insistencia. El caso que se plantea, 4 escaños y tres partidos empatados, es el ejemplo de que la ley D'Hont es inocente. Dicha ley se limita a repartir restos de votos. En el ejemplo, cualquier asignación de restos distinta a la ley D'Hont va a provocar los mismos inconvenientes. Por tanto, es el tamaño de la circunscripción la "culpable".
Saludos.
En la Cámara de Representantes de Uruguay tenemos representación proporcional de los partidos a nivel nacional, a la vez que hay diputados por cada departamento. Funciona bien.
El verdadero problema es que Metroscopia da vergüenza desde que cambió su metodología en septiembre del 2013 (esta vez publican la IDV y no el "voto probable declarado" que fue lo que se inventaron depués del esperpento de junio-julio cuando ocultaron una escuesta y luego se inventaron otra y la fecha de trabajo de campo).
Podemos es primera fuerza, eso es incuestionable habida cuenta de la IDV (si probamos a extrapolar sobre censo la IDV del CIS tenemos una probabilidad alta de acertar) pero mucha gente suelta lo de "esos votos desafectos que reuirán Podemos a última hora y recularán hacia el PP y el PSOE" cuando es evidente (como dijera Belén Barreiro) que el PP ha roto fidelidad y el PSOE no halla suelo. Los 4 millones de votantes que han dejado el PP se reparten entre Podemos (1 millón), UPyD+C`s (1 millón), PSOE y otros (1 millón) y abstención.
El PP se haya camino de la ucedización y el PSOE de una desmembración sin precedentes.
Además con la ley d`Hondt en la mano, si el PSOE baja 3 puntos más de la media que tiene en la gráfica de la wiki ( http://en.wikipedia.org/wiki/Opinion_polling_for_the_Spanish_general_election,_2015 ) y Podemos queda primero, la susodicha ley empezaría a regalar escaños a Podemos (circunscripciones de 5, 3 para Pod, las de 7, 4, las de 3, 2). Si nos fijamos en las encuestas (sus datos brutos) no es descabellado afirmar que Podemos se encamina hacia la absoluta y que el PSOE va camino de convertirse en el PRAE.
Por cierto, el dato de C`s es imposible con la IDV que saca.
Añádase a lo dicho que "ganar las elecciones" (en el sentido de ser el que más votos/escaños obtenga) en un escenario en que ninguno de los tres partidos podrá gobernar si no es con el apoyo de uno de los otros dos, se vuelve bastante irrelevante.
Dice Vd. para justificar el aumento de la imprecisión cuando aumenta el número de opciones, "El primero es que con las mismas 1,000 observaciones tenemos que estimar más parámetros y por tanto los intervalos de confianza (frecuentistas) o las posterioris (Bayesianos) serán más amplios" Y pregunto yo, ¿esto no podría resolverse aumentando el número de entrevistados? Es decir, ¿cuánto hay que aumentar el tamaño de la muestra para obtener resultados comparables en precisión a los del primer supuesto?
Por otra parte, si le he entendido bien, las encuestas bien hechas pueden ser muy precisas cuando solo hay dos opciones. Teniendo en cuenta que las cifras que se gastan en las campañas electorales son astronómicas, me pregunto (aunque consciente de que esto puede atentar contra lo más sagrado) si en sistemas como el norteamericano no podrían sustituirse por una encuesta.
Si, en parte se podria resolver con encuestas mas grandes. Es un problema numerico (el enlace que ponia explica el porque) determinar cuantas mas.
Lo que me da mucho mucho miedo es la caída del PSOE, que es El PSOE es el partido de la transición, el que enlaza a amplias clases populares con el sistema político.
Por tanto, la estrategia de Arriola de crear un marco de debate entre PP y Podemos es una gravísima irresponsabilidad.
Técnicamente, si se presentan 2 partidos, hay 3 opciones posibles: votar a uno de los 2 partidos, o no votar. Por otro lado, me pregunto qué diferencia hay entre utilizar una distribución binomial y una multinomial. La binomial permite estimar la proporción de votantes aunque existan más de 2 opciones, ya que cualquier número de opciones >2 siempre puede reducirse a dos (afirma que vota al partido X, ¿sí o no?). Me imagino que utilizando una multinomial se estiman todas las proporciones a la vez y esto debe tener algún tipo de ventaja.
"Por otro lado, me pregunto qué diferencia hay entre utilizar una distribución binomial y una multinomial. "
Gracias por el comentario. He evitado citar una binomial 🙂 En primer lugar porque una binomial es un caso particular de una multinomial. En segundo lugar porque, efectivamente, en 2012 habia mas opciones que votar PP/PSOE (no votar/votar en blanco/a partidos minoritarios etc.)
La clave de mi argumento es que:
1) Ahora la multinomial tiene mas parametros a estimar.
2) La "señal" es mas debil por la cercania de los partidos.
Preguntar de manera secuencial ("reducir a dos opciones" y hacer varias preguntas) es equivalente a una multinominal siempre y cuando no induzcas sesgos cognitivos (i.e. la gente te responda cosas distintas al preguntarles de una manera diferente). Pero si preguntasemos a un "robot" de manera simultanea o secuencial, no habria ni mas ni menos informacion.
Es cierto que el artículo no menciona la distribución binomial. He leído demasiado rápido…
Estoy de acuerdo con el argumento.
La verdad es que desde un punto de vista demoscópico la situación actual es muy interesante.
Quiero comentar un punto:
En un escenario de tres caballos ganadores y cuatro rezagados creo que hay menos incertidumbre que un escenario de únicamente tres caballos, dejando la abstención aparte. La razón es que los votos que pierda un caballo ganador en el primer escenario pueden repartirse entre sus rivales o "diluirse" en los rezagados. En el segundo escenario los vasos comunicantes son puros y las alteraciones más decisivas.
Y para No perder de vista el adelanto electoral en Catalunya
Interesante argumento. Tendria que hacer una simulacion al respecto 🙂 A ver si tengo tiempo.
Gracias por el interesante post.
Como bien dices, en el escenario actual, una encuesta de n=1000 no es suficiente para inferir predicciones fiables acerca del resultado electoral. Hazel propone como solución incrementar el tamaño de muestra de las encuestas. Es una buena solución, pero llevarla a la práctica depende de la decisión de los responsables de los medios que contratan encuestas, no de nosotros. Como alternativa, se me ocurre calcular la media (ponderada por tamaño de muestra) de las últimas encuestas disponibles. ¿Cree que permitiría obtener predicciones más fiables?
Con el fin de ver como funciona esta propuesta he realizado una simulación. Al igual que usted, he simulado 5000 encuestas de 1000 entrevistas cada una utilizando una distribución multinomial con probabilidades (0.36,0.32,0.32). He repetido este procedimiento 8 veces y posteriormente he calculado la media de esas 8 veces (en este caso no ha sido necesario hacer media ponderada por tamaño de muestra ya que se ha supuesto igual a 1000 en todos los casos). La justificación de este procedimiento es que no sólo disponemos de la encuesta de El País, sino que hay más medios que han publicado encuestas en las últimas semanas (Telecinco, El Mundo, El Diario, El Periódico, El Mundo, La Ser, La Sexta, etc) y esa información puede usarse.
Resultado de la simulación: Suponiendo que la verdadera intención de voto es (36%, 32%, 32%), realizar la media de 8 encuestas de 1000 entrevistados cada uno nos permite reducir la incertidumbre notablemente. El histograma del partido del 36% no se solapa con los histogramas de los partidos del 32%.
Enlace al gráfico:
http://subefotos.com/ver/?d8974f937f79a0549a8a6ff89c773c60o.jpg#codigos
Si. El resultado se puede mejorar mucho ponderando distintas encuestas. Es lo que hace Nate Silver en Estados Unidos. No quise entrar en el tema porque muchas de las encuestas en España no son comparables en terminos de metodologia y no queda claro que peso darles a cada una. Pero si, tienes toda la razon 🙂
Jesús, muy interesante. Una cosa que creo que haría más efectivo el argumento es mantener la distancia entre el primero y segundo en intención a voto cuando se agrega un tercer candidato. Ejemplo, en lugar de la 36, 32 y 32, sería ver que pasa con un 40, 30 y 30. De esta manera, creo que sería más comparable el porcentage de veces en que la diferencia de 10 puntos en la encuestta se traduciría en una victoria entre la situación A (distribución binomial) y la situación B (distribución multinomial).
Los comentarios están cerrados.